


Introduction
Hey Guys, this article will give you a quick introduction of pandas as to what is Pandas, why you should use Pandas, what can you do with Pandas, and the supported Pandas data types. It can help you make sure if Pandas is what you are looking for or you should learn pandas or not.
If you’re looking for data science then you must have heard of this library at least once. Pandas is the most famous/downloaded library for data science.
Why? Because it is super fast and makes working with datasets so much easier. We’re gonna talk about everything from series to DataFrames, from creating a new DataFrame to reading an old dataset everything.
Prerequisites
You should have a basic understanding of Python especially dictionaries, lists, and tuples. Some basic knowledge of NumPy will also be helpful as arrays are often used in Pandas Series and DataFrames along with the dictionaries.
If you want to learn NumPy then check out our amazing tutorial on NumPy Arrays which covers everything that you need to know about NumPy.
What is Pandas?
Pandas is a high-performance open-source library for data analysis in Python developed by Wes McKinney in 2008. Over the years, it has become the de-facto standard library for data analysis using Python.
Why Pandas?
The benefits of pandas over using the languages such as C/C++ or Java for data analysis are manifold:
- Data representation : It can easily represent data in a form naturally suited for data analysis via its DataFrame and Series data structures in a concise manner. Doing the equivalent in C/C++ or Java would require many lines of custom code, as these languages were not built for data analysis but rather networking and kernel development.
- Data sub-setting and filtering : It provides for easy sub-setting and filtering of data, procedures that are a staple of doing data analysis.

Features of Pandas
- It can process a variety of data sets in different formats: time series, tabular heterogeneous arrays, and matrix data.
- It facilitates loading and importing data from varied sources such as CSV and DB/SQL.
- It can handle a myriad of operations on data sets: sub-setting, slicing, filtering, merging, groupBy, re-ordering, and re-shaping.
- It can deal with missing data according to rules defined by the user and developer.
- It can be used for parsing and managing (conversion) of data as well as modeling and statistical analysis.
- It integrates well with other Python libraries such as stats models, SciPy, and Scikit-learn.
- It delivers fast performance and can be speeded up even more by making use of Cython (C extensions to Python).
Setting Up
Now, I’m not a big fan of Jupyter Notebook but it makes the data science easier to understand because you know exactly which block is executing which code.
Since most people find it difficult to use Jupyter Notebook standalone without Anaconda, We’ll stick to our old favorite – Default IDLE
Installing Pandas and JupyterLab
Now for those who do want to use Jupyter Notebook, if you have anaconda installed, it’s fine to skip the whole setting up section because Pandas comes pre-installed with Anaconda. If you don’t have Anaconda, continue reading
Open your pip and install Jupyter lab as:
pip install jupyterlab
This is it, it will install Jupyter Notebook in your system. Also, you may also be aware that there’s a jupyter library too. We aren’t going to install that because it is no longer updated and this just gets the job done fairly well.
Check out this video. It might help you set up Jupyter Lab

Now, I won’t be explaining how to use Jupyter Notebook here in this tutorial because this is out of the scope of this tutorial. So, we’ll just get to the point. Open your terminal, cd to the path where you want to access files using Jupyter, and open Jupyter Notebook there. I will make a video on that in future tutorials but this article is about Pandas so we’re gonna skip that.
Now all you have to do is install Pandas. It is fairly easy to do so. Just open pip and type
pip install pandas
This will install pandas in your computer.
Syntax
The general convention is that you import pandas with an alias name pd. It is not necessary that you import it with this name but it is the recommended way to do it and you’ll find it this way in most of the places. So, it will improve readability of your code.
import pandas as pd
Pandas Data Structures
Pandas supports two main type of Data Structures. Series and DataFrames!


Series
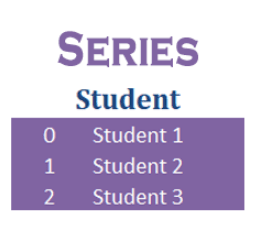
Pandas Series is the one-dimensional labeled array just like the NumPy Arrays. The difference between these two is that Series is mutable and supports heterogeneous data. So Series is used when you have to create an array with multiple data types. Imagine a table, the columns in that table are Series and the table is a DataFrame.
Take a look at the image below. It will help you visualize better.

Creating Series
Syntax for creating Pandas Series is:
import pandas as pd
s = pd.Series(data=None, index=None, dtype=None, name=None, copy=False, fastpath=False)
NOTE: ‘S’ of the pd.Series is capital. People tend to forget that.
This syntax may seem a little overwhelming but you do not need to focus on all the parameters. Most of the time you will only be using the data and index parameters but we will be discussing all the parameters here. But let’s first create example Series here.
import pandas as pd
s = pd.Series(["Coding Ground",1,5.8,True])
print(s)
Output will be:
0 Coding Ground
1 1
2 5.8
3 True
dtype: objectNow that we have a Series of consisting data of multiple datatypes, we can proceed further.
data: Sequence, most preferably list but can also be dictionary, tuple, or an array.
It contains data stored in Series.
index: This is optional. By default, it takes values from 0 to n but you can define your own index values. Now there are two ways to define index,
s = pd.Series(["Coding Ground",1,5.8,True],index=["String","Integer","Float","Boolean"])
The output will be
String Coding Ground
Integer 1
Float 5.8
Boolean True
dtype: objectYou can also set index using .index method as
s.index = [1,2,3,4]
And it will work same as defining index in parameters. Output will be
1 Coding Ground
2 1
3 5.8
4 True
dtype: objectdtype: It is the datatype of the Series. If not defined, it will take values from the series itself. If it’s the same for all element, it will show a specific data type such as int else it will show Object.
name: It is the name given to your pandas series
s = pd.Series(["Coding Ground",1,5.8,True],index=["String","Integer","Float","Boolean"],name="Pandas Series")
It will add a name “Pandas Series” to your Series. The output will be
String Coding Ground
Integer 1
Float 5.8
Boolean True
Name: Pandas Series, dtype: objectYou can also do the same using s.name = “Pandas Series”
copy: It creates a copy of the same data in variable(s). By default it is set to False i.e., if you change the data in one variable, it’ll change in all variables wherever the data is stored. Change it to True and all the locations where the data is store will be independent of each other. For example,
s = pd.Series(["Coding Ground",1,5.8,True],index=["String","Integer","Float","Boolean"],name="Pandas Series")
ss = s
ss[1] = 2
print(ss)
print(s)
The output would be:
#SS
String Coding Ground
Integer 2
Float 5.8
Boolean True
Name: Pandas Series, dtype: object
#S
String Coding Ground
Integer 2
Float 5.8
Boolean True
Name: Pandas Series, dtype: objectYou can clearly see that even though you changed the value of the second element in ss, it automatically got changed in s. This is because copy by default is False. Set it to True
ss = s.copy()
ss[1] = 3
print(ss)
print(s)
This will create a new copy in ss and they will not share same data location point anymore.
So, changing one will not change another.
#SS
String Coding Ground
Integer 3
Float 5.8
Boolean True
Name: Pandas Series, dtype: object
#S
String Coding Ground
Integer 2
Float 5.8
Boolean True
Name: Pandas Series, dtype: objectfastpath: Fastpath is an internal parameter. It cannot be modified. It is not described in pandas documentation so you may have to take a look here.
DataFrames
DataFrame is the most commonly used data structure in pandas. DataFrame is a two-dimensional labeled array i.e., Its column types can be heterogeneous i.e. of varying types. It is similar to structured arrays in NumPy with mutability added.
It has the following properties:
- Similar to a NumPy ndarray but not a subclass of np.ndarray.
- Columns can be of heterogeneous types e.g char, float, int, bool, and so on.
- A DataFrame column is a Series structure.
- It can be thought of as a dictionary of Series structures where both the columns and the rows are indexed, denoted as ‘index’ in the case of rows and ‘columns’ in the case of columns.
- It is size mutable that means columns can be inserted and deleted


Creating DataFrames
Syntax for creating Pandas DataFrames is:
pandas.DataFrame(data=None, index: Optional[Collection] = None, columns: Optional[Collection] = None, dtype: Union[str, numpy.dtype, ExtensionDtype, None] = None, copy: bool = False)
data: You can input several types of data as below:
- Dictionary of 1D ndarrays, lists, dictionaries, or Series structures.
- 2D NumPy array
- Structured or record ndarray
- Series structures
- Another DataFrame structure
Now for example, you can create a dataframe like this:
import pandas as pd
ls = ["item 1","item 2","item 3","item 4"]
df = pd.DataFrame(ls)
print(df)
And the output will be
0
0 item 1
1 item 2
2 item 3
3 item 4But yeah, there’s no point in creating a DataFrame like that. You could just create a series for that. Now moving onto a full tabular dataframe.
Now for the sake of simplicity, we’re going to use this data.
import pandas as pd
data = {"Student":["Student1","Student2","Student3"],"Age":[18,19,20]}
df = pd.DataFrame(data)
print(df)
The output of this code would be
Student Age
0 Student1 18
1 Student2 19
2 Student3 20See how keys of dictionary became the columns.
index: index in DataFrame is rows.
df.index = ["row1","row2","row3"]
This will result in
Student Age
row1 Student1 18
row2 Student2 19
row3 Student3 20columns: It is the same as keys in a dictionary.
Suppose now you want to change the columns from “student” to “name of student” and from “Age” to “Age of Student”. You could do it easily as:
df.columns = ["Name of Student","Age of Student"]
And the output will be
Name of Student Age of Student
row1 Student1 18
row2 Student2 19
row3 Student3 20So, this is it, we have covered all the parameters of DataFrames along with an example.
dtype: The datatype of Data in the DataFrame
copy: Same usage as Series, allows different location of same data.
We aren’t going to discuss the copy parameter here because that would require a lot of examples and new functions which are out of scope of this tutorial. We will be discussing these things in details in the future lessons.
Conclusion
Congratulations on completing this tutorial. It was your first step in deciding whether you should learn Pandas or not and since you’re reading this, you made the right choice.
Personally, I recommend learning Pandas because why not? It is the most powerful library and if data science is what you’re aiming for then you’ll see this library a lot.
You should set up Jupyter Notebook or preferably Anaconda. Use IDLE only if you can’t have Jupyter Notebook or Anaconda. IDLE will be a little bit slower when processing data compared to Anaconda but that’s fine. I mean you don’t necessarily need it but it will help you understand better. Also one more thing, remember that S of pd.Series and D of pd.DataFrame is in caps. People make that mistake a lot and their program fails.
So, now I want to ask you, can you make a DataFrame using Series?
If yes, how?
Comment down the answer below!
So, guys, this is it for this tutorial, we’ll be looking at more advanced topics in the future.
Happy Coding!



